
Project information
- PL: Python
- Libraries: pandas, nltk, spaCy, scikit-learn
- Skills: Data Cleaning, Natural Language Processing, Data Extraction
- Project date: 2024
- Project URL: Kaggle
Overveiw
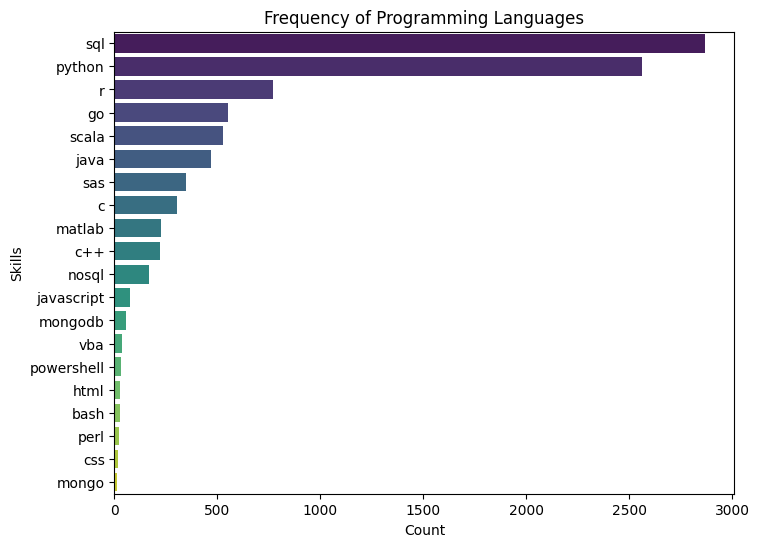
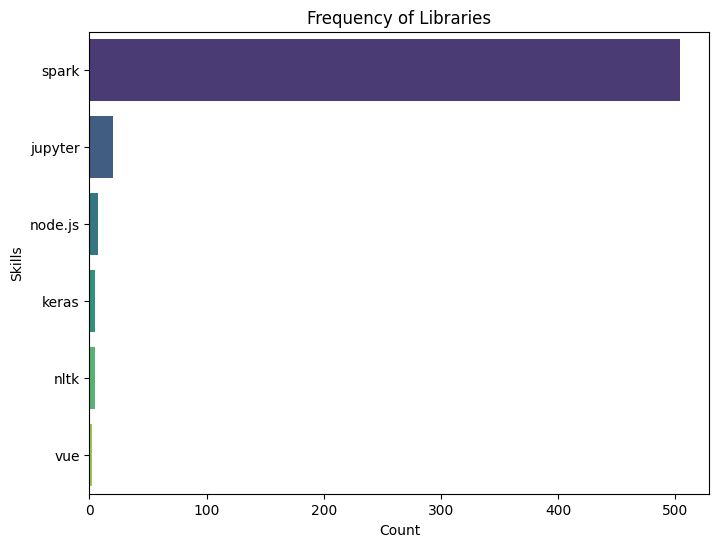
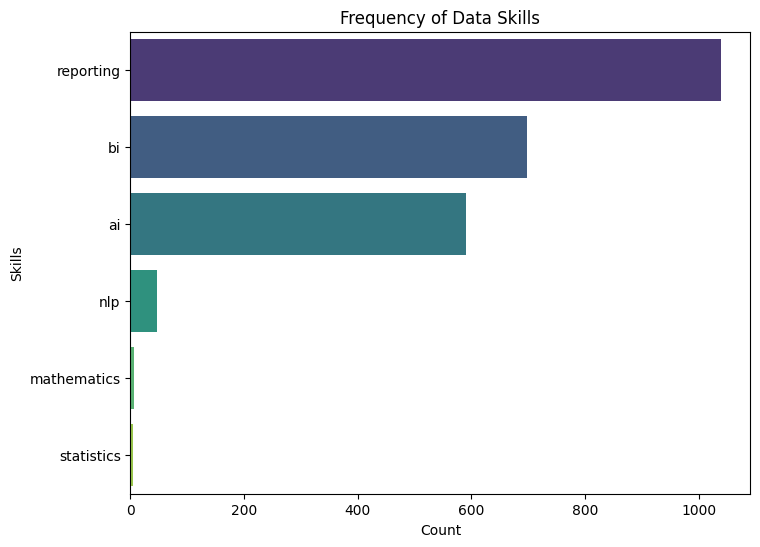
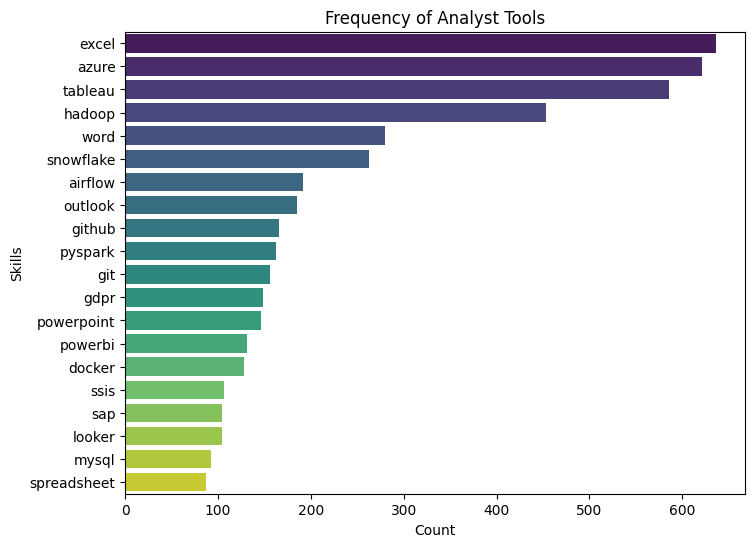
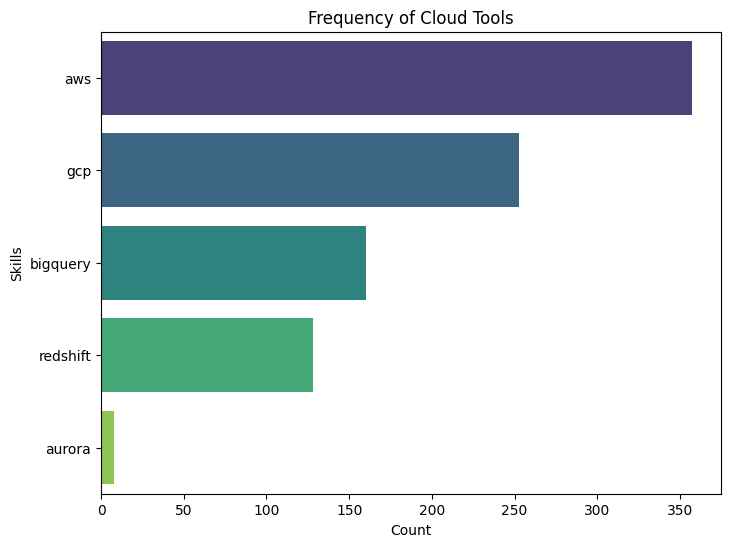
This project is focused on extracting key information from job descriptions using natural language processing (NLP) techniques. The goal is to parse job descriptions to identify and extract details such as job title, salary, skills required, and more. This project provides valuable insights for job market analysis and helps in automating the process of job data extraction. The project uses Python and NLP libraries like spaCy and nltk to perform the parsing and data extraction.
Methodology
- Data Collection: Collected job descriptions from various job listing websites.
- Data Cleaning: Cleaned the data to remove any inconsistencies and irrelevant information.
- Text Processing: Used natural language processing (NLP) techniques to preprocess the text data, including tokenization, stop word removal, and entity recognition.
- Information Extraction: Applied NLP models to extract key information such as job title, salary, required skills, and company name from the job descriptions.
- Data Storage: Stored the extracted information in a structured format for further analysis and visualization.